Graphx Convolution
Anh-Duc Nguyen, Seonghwa Choi, Woojae Kim, and Sanghoon Lee
International Conference on Computer Vision (ICCV 2019)
Abstract
In this paper, we present a novel deep method to reconstruct a point cloud of an object from a single still image. Prior arts in the field struggle to reconstruct an accurate and scalable 3D model due to either the inefficient and expensive 3D representations, the dependency between the output and number of model parameters or the lack of a suitable computing operation. We propose to overcome these by deforming a random point cloud to the object shape through two steps: feature blending and deformation. In the first step, the global and point-specific shape features extracted from a 2D object image are blended with the encoded feature of a randomly generated point cloud, and then this mixture is sent to the deformation step to produce the final representative point set of the object. In the deformation process, we introduce a new layer termed as GraphX that considers the inter-relationship between points like common graph convolutions but operates on unordered sets. Moreover, with a simple trick, the proposed model can generate an arbitrary-sized point cloud, which is the first deep method to do so. Extensive experiments verify that we outperform existing models and halve the state-of-the-art distance score in single image 3D reconstruction.
Method
Image encoding
We use a VGG-like architecture as in Pixel2mesh to encode the input image (middle branch).
Point-specific feature
We extract a feature vector for each individual point by projecting the points onto the feature maps as illustrated in the figure (top branch). Concretely, given an initial point cloud, we compute the 2D pixel coordinate of each point using camera intrinsics. Since the resulting coordinates are floating point, we resample the feature vectors using bilinear interpolation.
Global features
First, we process the initial point cloud by a simple MLP encoder composed of several blocks of FC layers to obtain features at multiple scales. We note that the number of scales here is equal to that of the image feature maps, and the dimensionality of the feature is the same as the number of the feature map channels at the same scale. Then, we apply AdaIN in style transfer to the point cloud features and image feature maps at the same scale (bottom branch).
Feature extraction
The point-specific and global features are concatenated into a long feature vector and this feature vector can be decoded into the 3D point cloud representation of the given object.
Graphx convolution
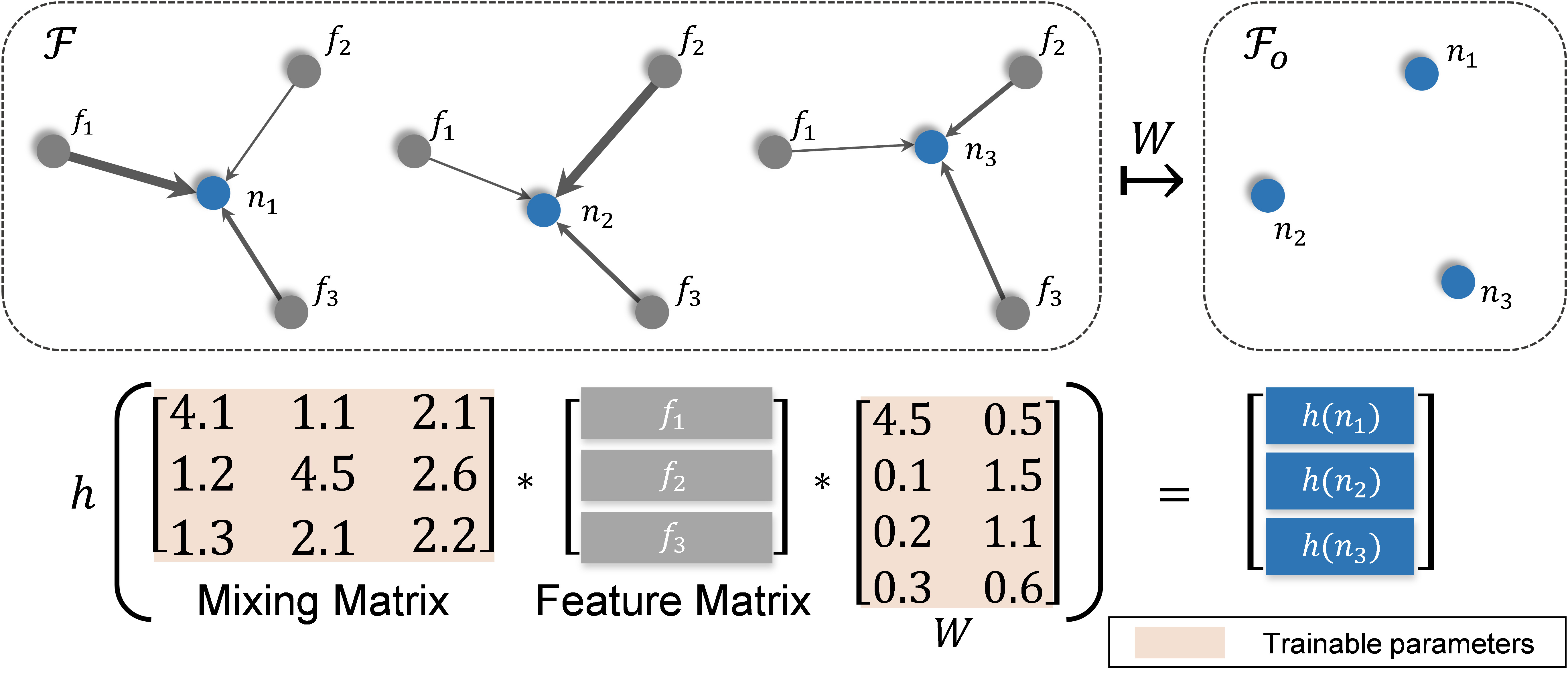
Deformation network
The deformation network consists of several Graphx layers. Also, different block types are made of Graphx. For more details, please refer to the paper and the supplementary material.
Results
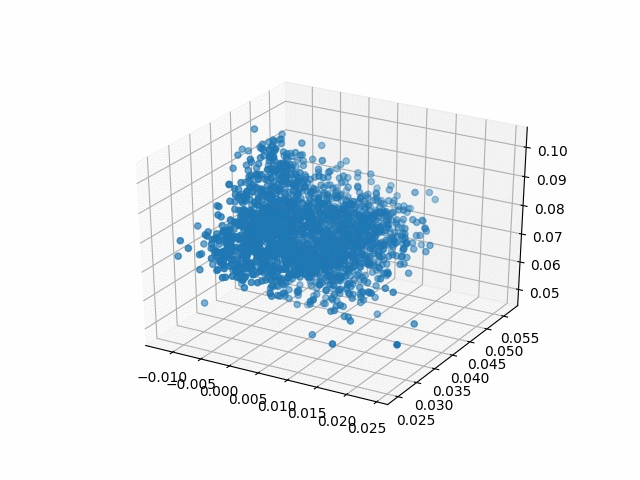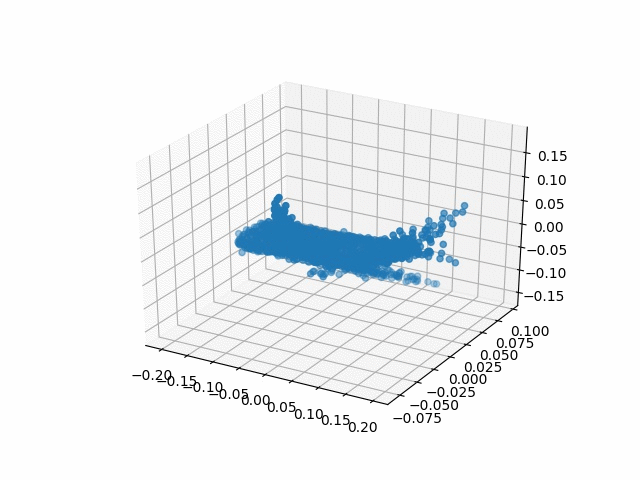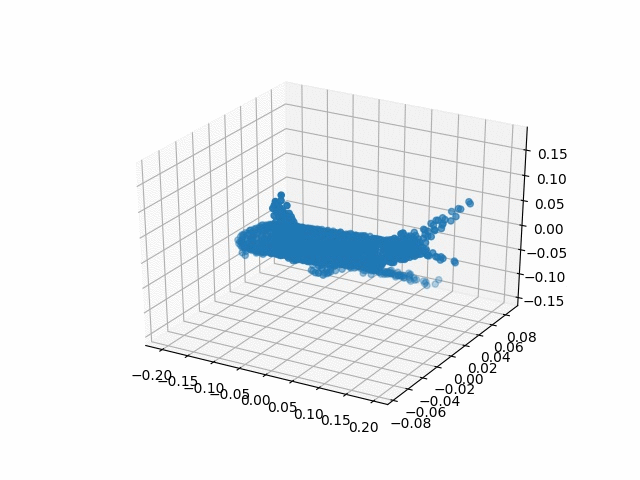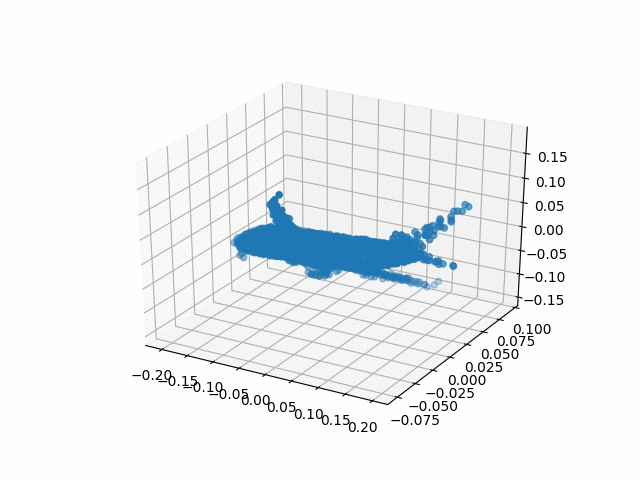
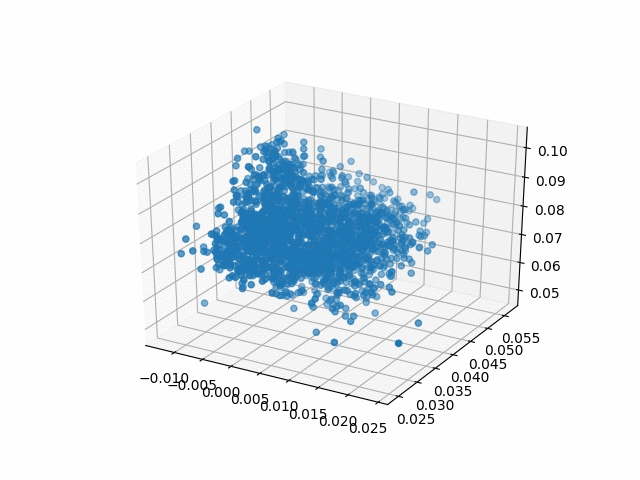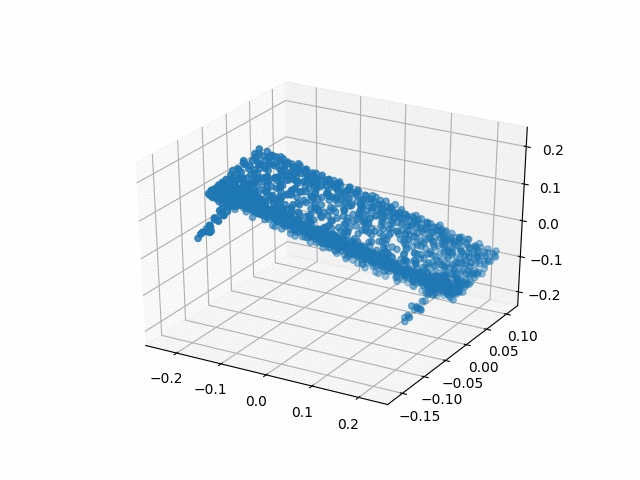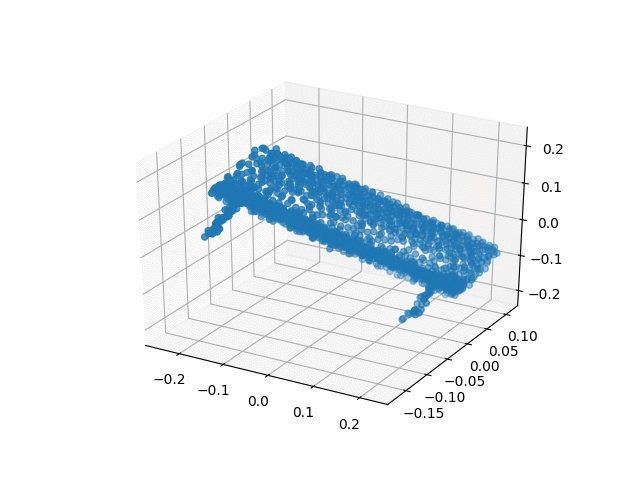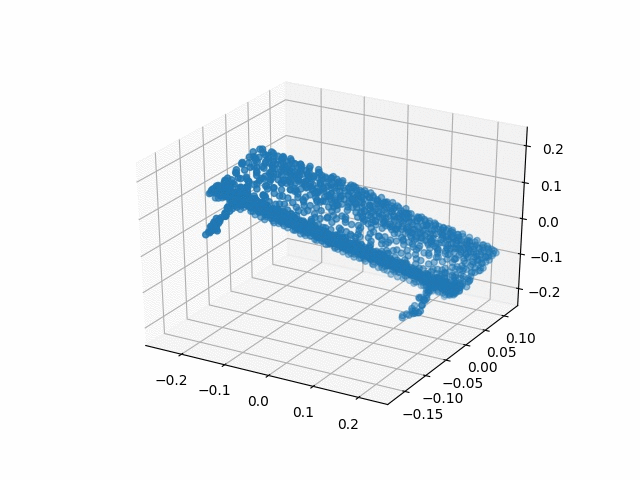
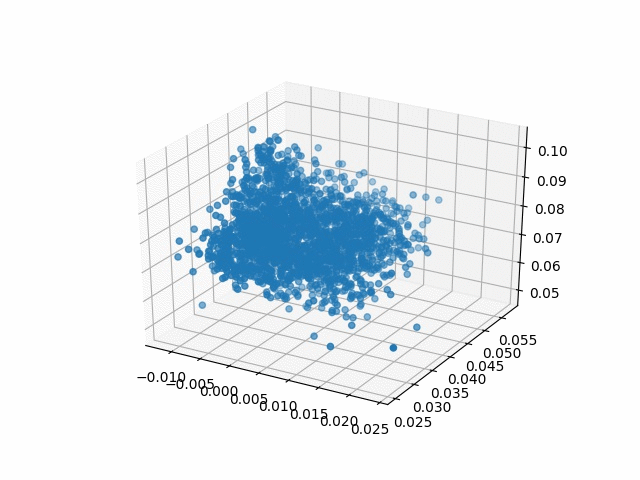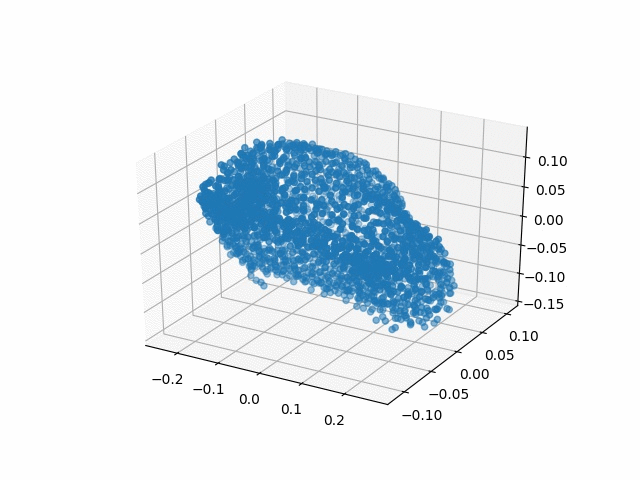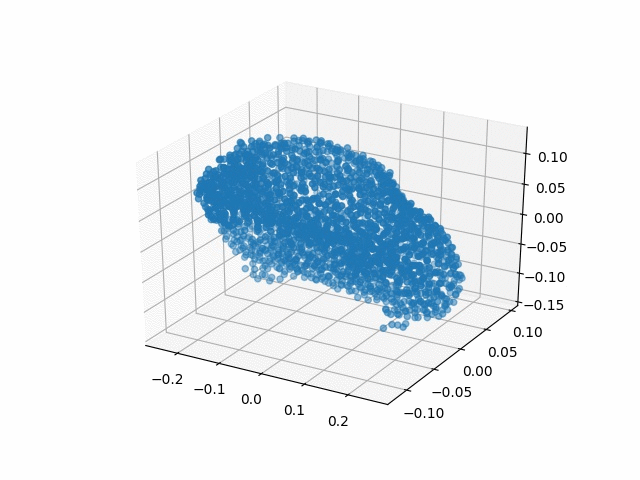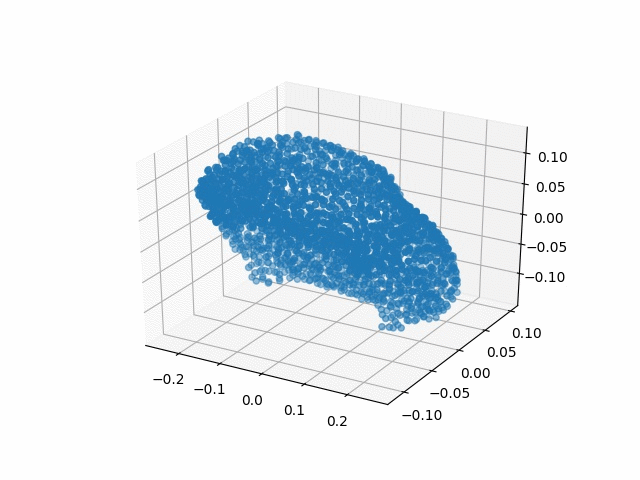
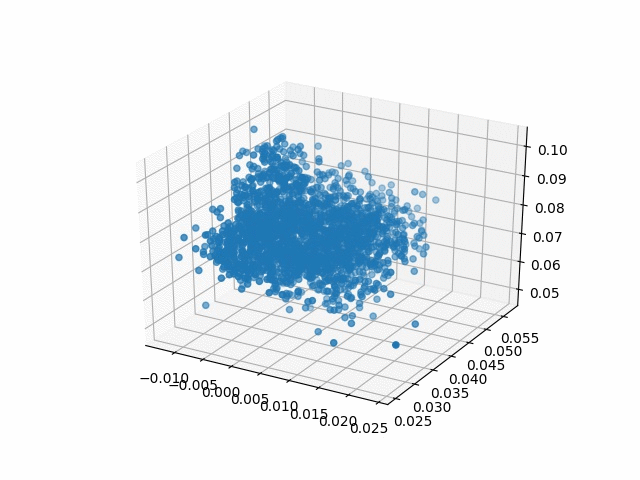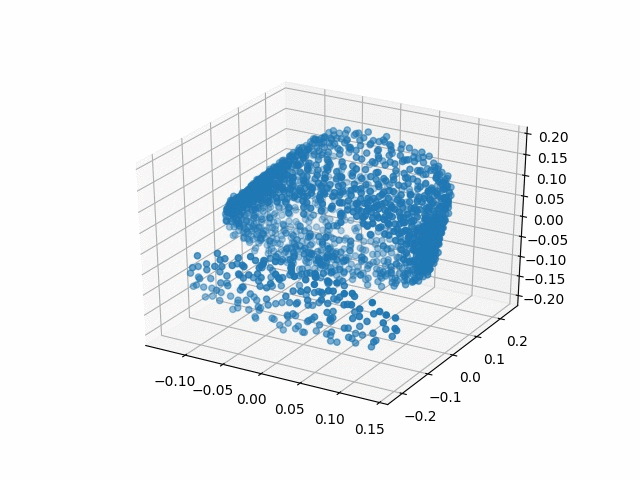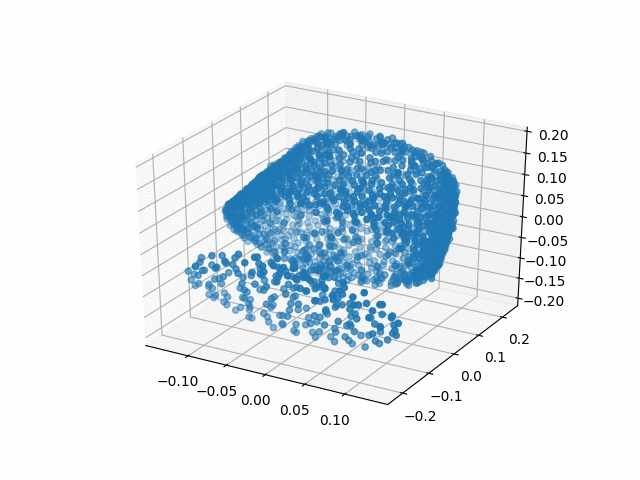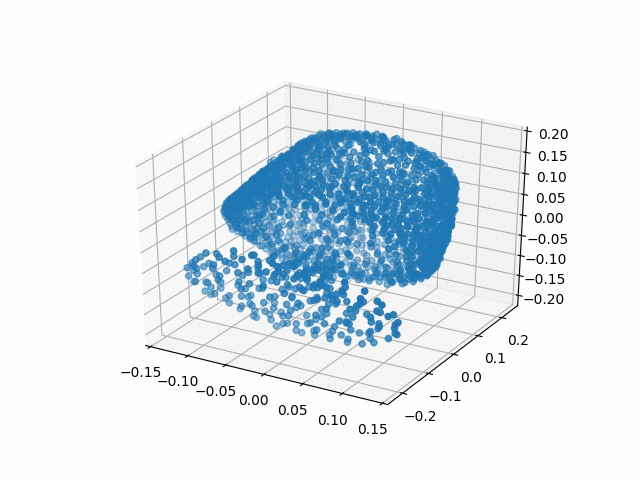
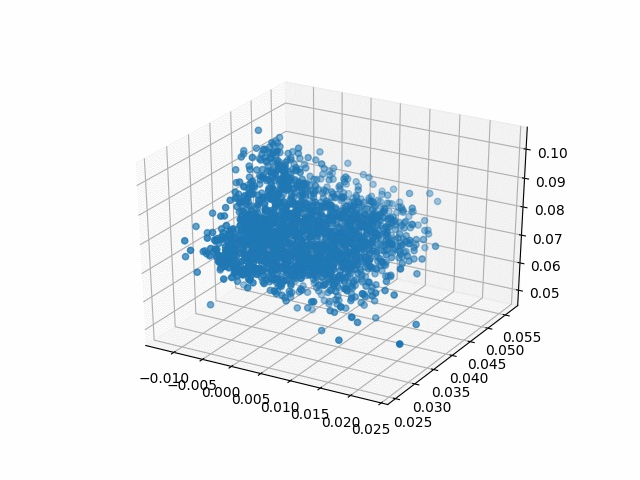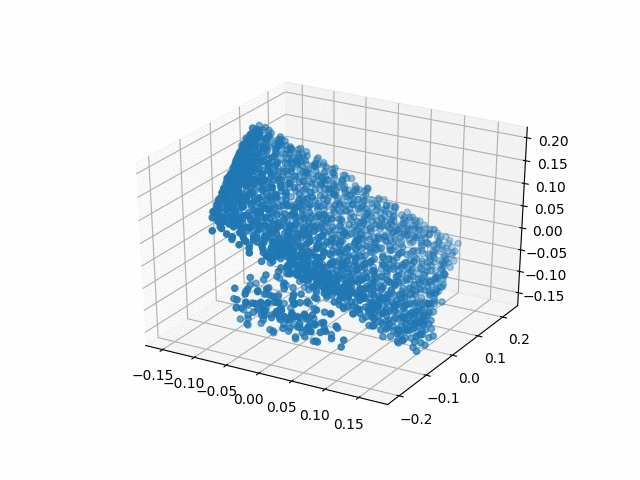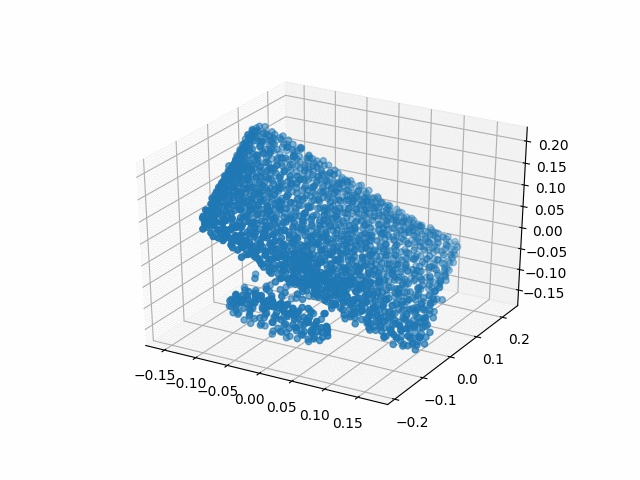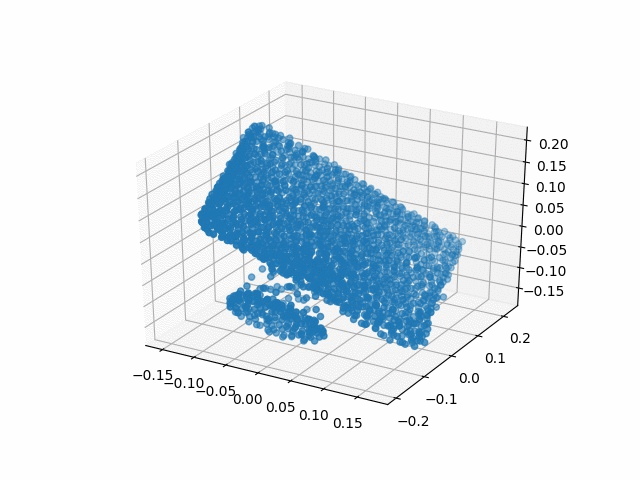
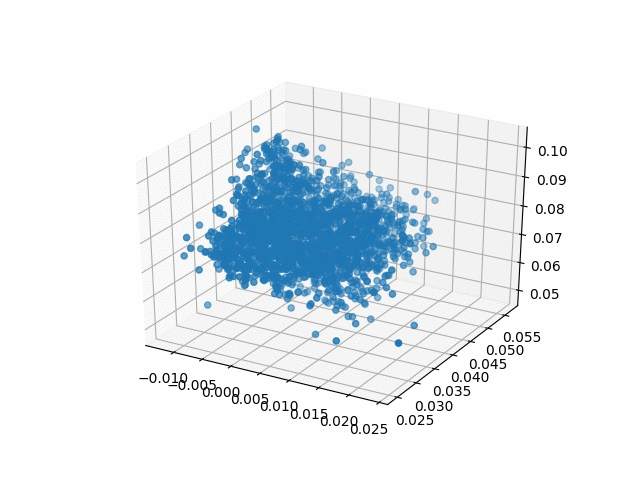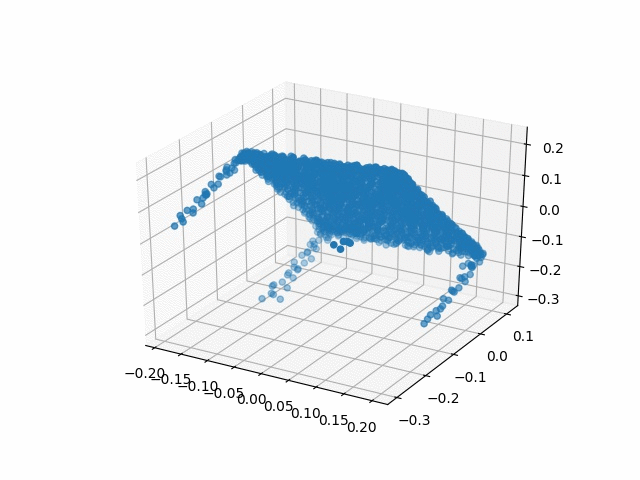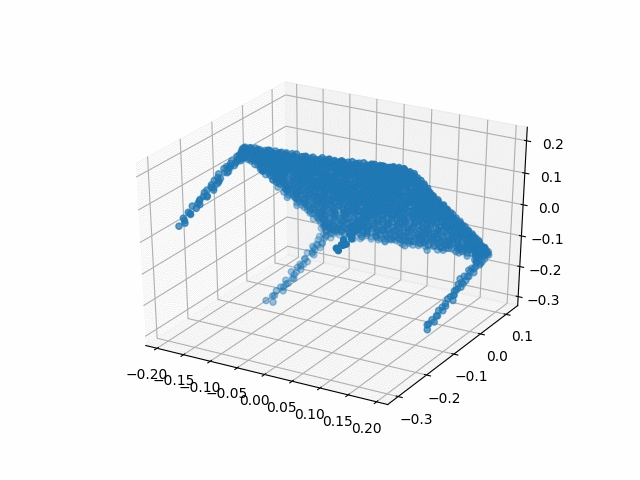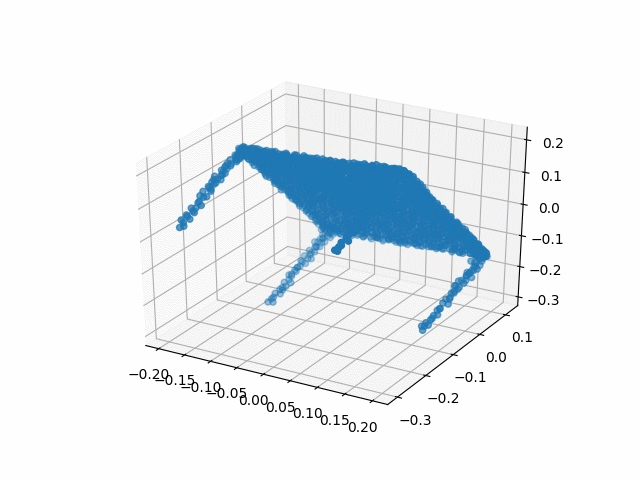

| Methods | CD | IoU |
|---|---|---|
| 3D-R2N2 | 1.445 | 0.631 |
| PSG | 0.593 | 0.640 |
| Pixel2mesh | 0.591 | - |
| GAL | - | 0.712 |
| Ours (UpResGraphX) | 0.252 | 0.725 |