Multiple Arbitrary Style Transfer
Anh-Duc Nguyen, Seonghwa Choi, Woojae Kim, and Sanghoon Lee
IEEE International Conference on Acoustics, Speech, and Signal Processing 2019 (ICASSP 2019)
Abstract
We re-define multimodality and introduce a simple approach to multimodal and arbitrary style transfer. Conventionally, style transfer methods are limited to synthesizing a deterministic output based on a single style, and there has been no work that can generate multiple images of various details, or multimodality, given a single style. In this work, we explore a way to achieve multimodal and arbitrary style transfer by injecting noise to a unimodal method. This novel approach does not require any trainable parameters, and can be readily applied to any unimodal style transfer methods with separate style encoding sub-network in literature. Experimental results show that while being able to transfer an image to multiple domains in various ways, the image quality is highly competitive with contemporary models in style transfer.
Method
Baseline
For style transfer, we utilize AdaIN, a state-of-the-art style transfer method in literature. The network architecture is shown in the figure below. The figure is reproduced from the original paper.
How to make the baseline produce multiple outputs?
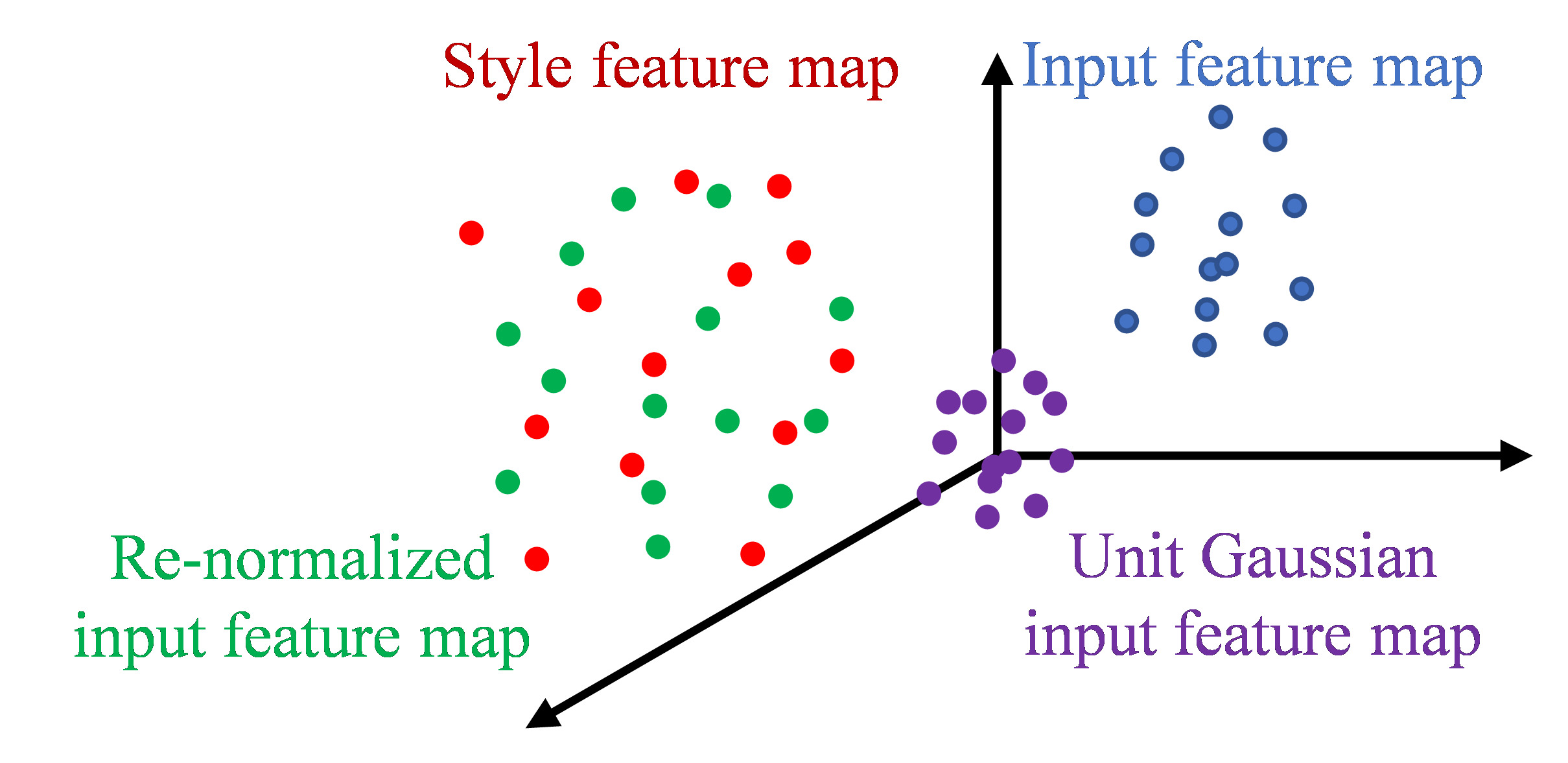
Style transfer can be done by transferring the statistics between the feature maps of an input and a style image. Visually, the process can be illustrated in the figure below, which shows the re-normalization of an input feature map (blue cloud) using the statistics of a style feature map (red cloud). We conjecture that by shifting the point cloud to a new position, the output (green cloud) can represent a new style (for e.g., a thick stroke), and by scaling the map, the network can control the influence of that style in the result (for e.g., how dominant it is compared to other features). Thus, modifying the scales and preserving the means of the feature maps can produce different features without distorting the given style. Moreover, from the feature space point of view, a linear combination of feature map is as good as the natural basis because it is the feature space that contains semantic information rather than each individual unit. Having these insights, in order to produce different characteristics in the outputs, we can utilize different combinations of the style feature maps encoded by the VGG19 encoder.
More details on how to combine features and train the network can be found in the paper.
Results
Qualitative results
For references, we chose the original AdaIN (the first two rows) and Multimodal Transfer (the last row).


Ablation study
We experimented with different distribution supports for the noise. Any noise with mean different from 1 (for e.g., 2) results in complete failure. Regarding the noise support, we additionally tested the network with noise ranges of [0.25; 1.75] (second to last image) and [0; 2] (last image).
