Distribution Padding
Anh-Duc Nguyen, Seonghwa Choi, Woojae Kim, Jinwoo Kim, Sewoong Ahn, and Sanghoon Lee
IEEE Conference on Image Processing 2019 (ICIP 2019)
Abstract
Even though zero padding is usually a staple in convolutional neural networks to maintain the output size, it is highly suspicious because it significantly alters the input distribution around border region. To mitigate this problem, in this paper, we propose a new padding technique termed as distribution padding. The goal of the method is to approximately maintain the statistics of the input border regions. We introduce two different ways to achieve our goal. In both approaches, the padded values are derived from the means of the border patches, but those values are handled in a different way in each variant. Through extensive experiments on image classification and style transfer using different architectures, we demonstrate that the proposed padding technique consistently outperforms the default zero padding, and hence can be a potential candidate for its replacement.
Method


Results
Classification
In this task, we trained CNNs on the training set of CIFAR- 10, which contains 50,000 images equally distributed in 10 categories. We slightly resized the images from 32x32 to 48x48 so that the valid convolution can be carried out in the late layers. To verify the benefit of the proposed padding scheme, we enlisted two of the most well-known network architectures: VGG19 and ResNet34. While VGG19 is a vanilla stack of convolutional layers with 3x3 filters, ResNet34 is made up of residual blocks in which information flow is enhanced by an identity mapping from early layers. We note that for ResNet34, we removed the first pooling layer and for VGG19, we used batch normalization after each convolutional layer and discarded all the fully connected layers as well. We optimized the multinoulli cross-entropy loss between the softmax outputs and ground truth labels using Adam. We considered zero padding, reflection padding, and partial-convolution-based padding as references in our benchmark. For each padding scheme, we ran totally 5 times, each time 100 epochs. We tested the networks on the test set every 1,000 iterations to plot the classification error rates. Needless to say, except for padding, we kept all settings the same.
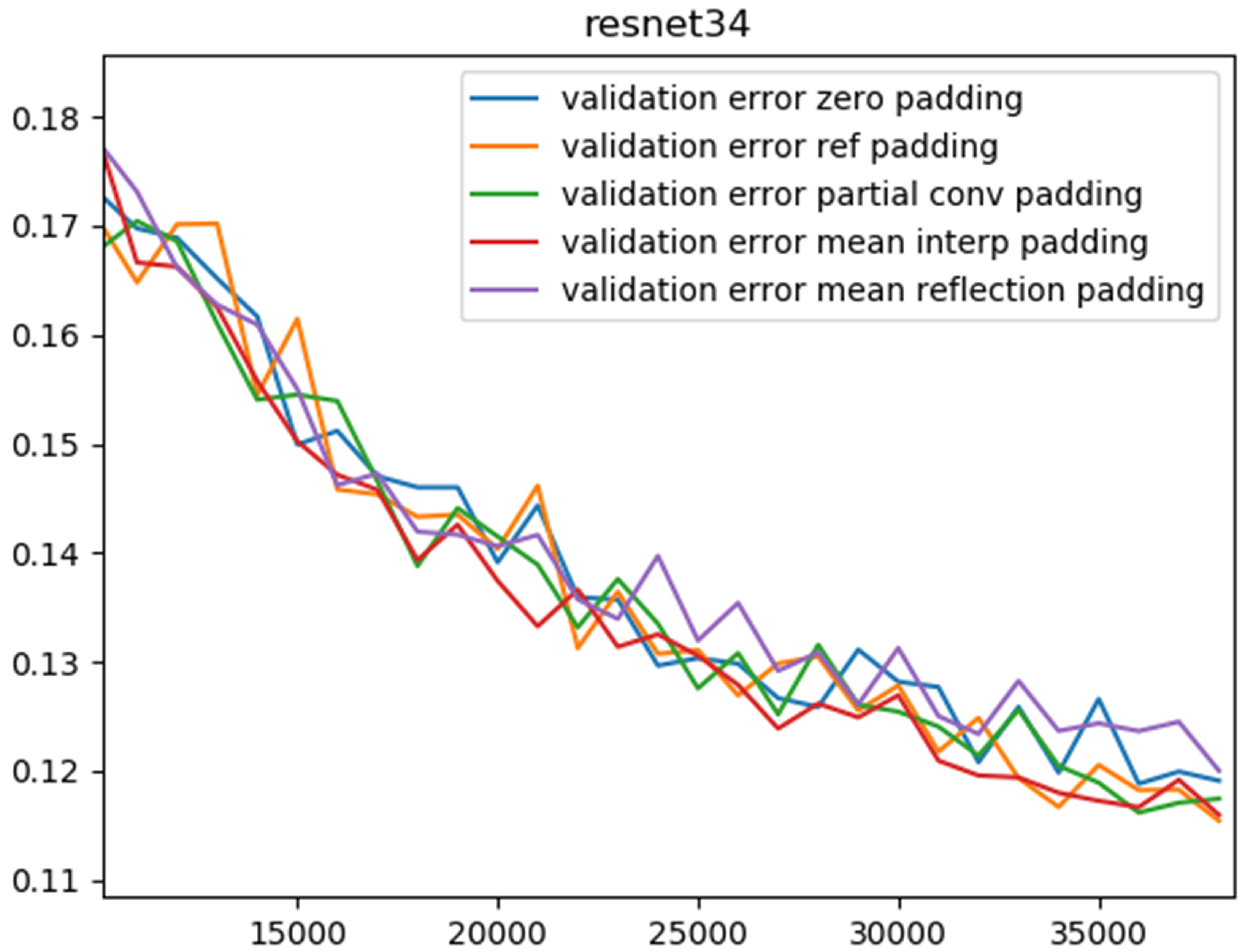
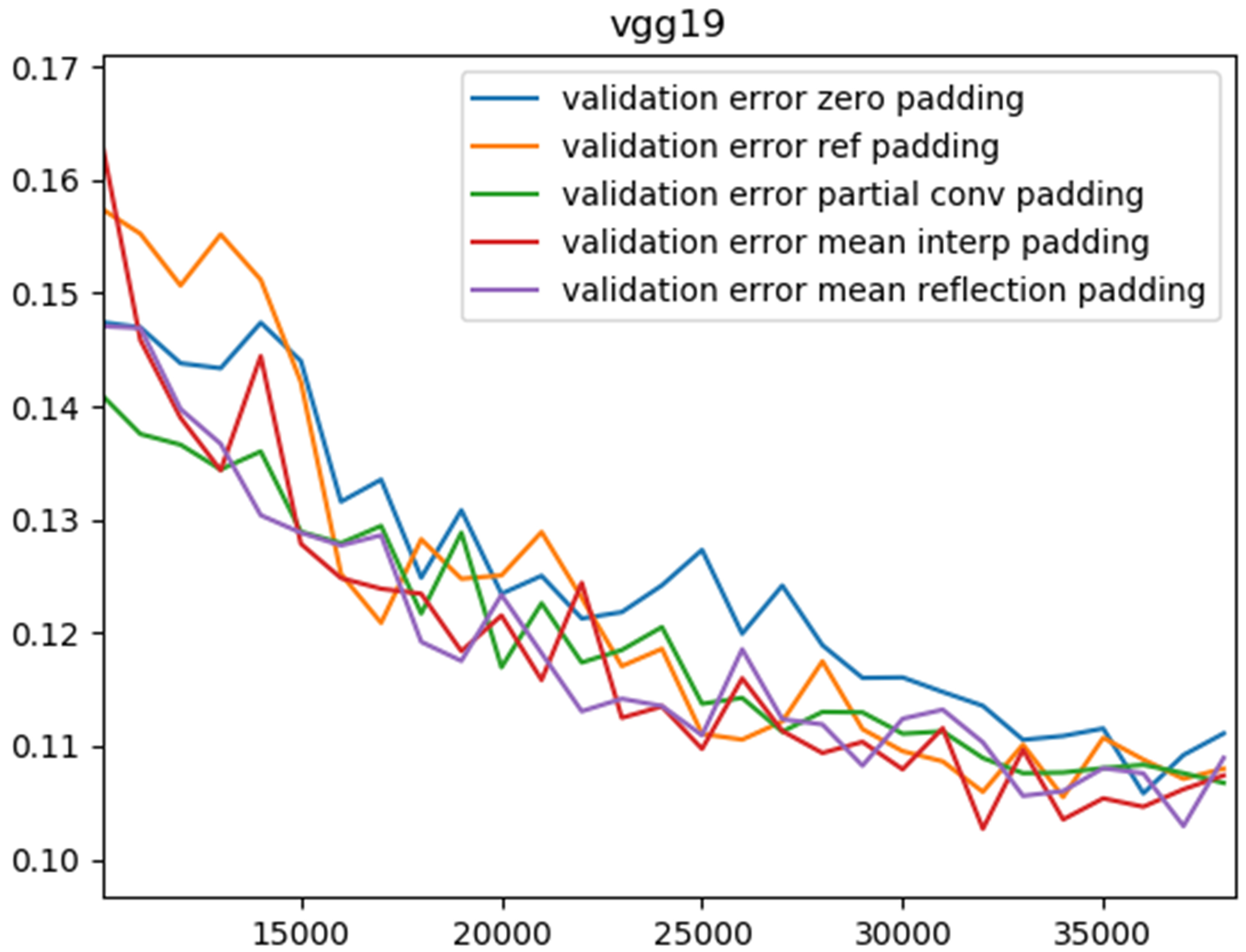
| Padding scheme | VGG19 | ResNet34 |
|---|---|---|
| Zero | 10.97 | 12.09 |
| Reflection | 10.80 | 11.78 |
| Partial-convolution | 10.77 | 11.80 |
| Mean-interpolation | 10.54 | 11.74 |
| Mean-reflection | 10.67 | 12.33 |
Style transfer
For the style transfer task, we employed WCTnet as the backbone. The method works by hooking up five different autoencoding models together and the transfer of style is carried out by a whitening and coloring transform in the latent space of each network. The encoders are different parts of a pre-trained VGG19 and the decoders are basically symmetric to the corresponding encoders. To benchmark a padding scheme, we employed it in both the VGG encoder and the decoders. We trained the decoders on the MS COCO training split for 3 epochs using the default hyperparameter choices. The testing was carried out on a separate set provided in the original paper. A complete list of settings can be found in the original paper. For references, we displayed only the results by zero padding and reflection padding because we failed to train the largest decoder using partial-convolution padding with the default hyperparameters.
